


Alice has $100 in her bank account and deposits $50 at a branch. The transaction completes, and she receives confirmation that her balance is now $150. If she checks her balance at a nearby ATM immediately afterward, should it also return $150? If it does not, is the system malfunctioning, or is it behaving exactly as designed?
These questions point to a deeper issue in distributed systems. Modern systems rarely store data on a single server. Instead, data is replicated across multiple servers, often in different regions. Updates must be transmitted between nodes, and because of message delays, bandwidth limits, and asynchronous communication, replicas do not apply those updates at the same time. As a result, clients reading the same data from different servers can temporarily observe different states.
Consistency is about the guarantees a system provides in that environment. After a write commits, what are clients allowed to observe? Must every read reflect the latest committed state? Is some lag acceptable? Are reads required to respect global ordering? Or is it enough that replicas eventually converge on the latest write? Consistency levels formalize these questions by defining how reads can relate to committed writes.
Rather than treating consistency as a single property, distributed systems expose a spectrum of models, each defining a different relationship between reads and committed writes. This article explains the six major consistency guarantees used in distributed systems with replicated storage, including strong consistency, bounded staleness, consistent prefix, monotonic reads, read-my-writes, and eventual consistency, and shows how they differ in practice.
For deeper visual explanations and related walkthroughs, you can also explore the consistency tutorial on Rialo Learn.
What is consistency?
In distributed systems, “consistency” can be understood from two perspectives: the server’s and the client’s.
Server-side consistency concerns the correctness and durability of committed writes. It requires that once a write commits, the resulting state is valid according to the system’s rules and that committed writes are never lost, rolled back, or partially applied. In other words, the database must remain internally consistent after every committed update, and committed writes must not be reverted.
For example, Alice has $100 in her account and deposits $50. If the write is committed, her balance must be $150. If she later deposits another $50 and that write also commits, her balance must become $200. A result such as $150 after the second deposit would imply that a previously committed write was lost or improperly reverted. Server-side consistency ensures that committed writes produce correct state transitions and remain durable once finalized.
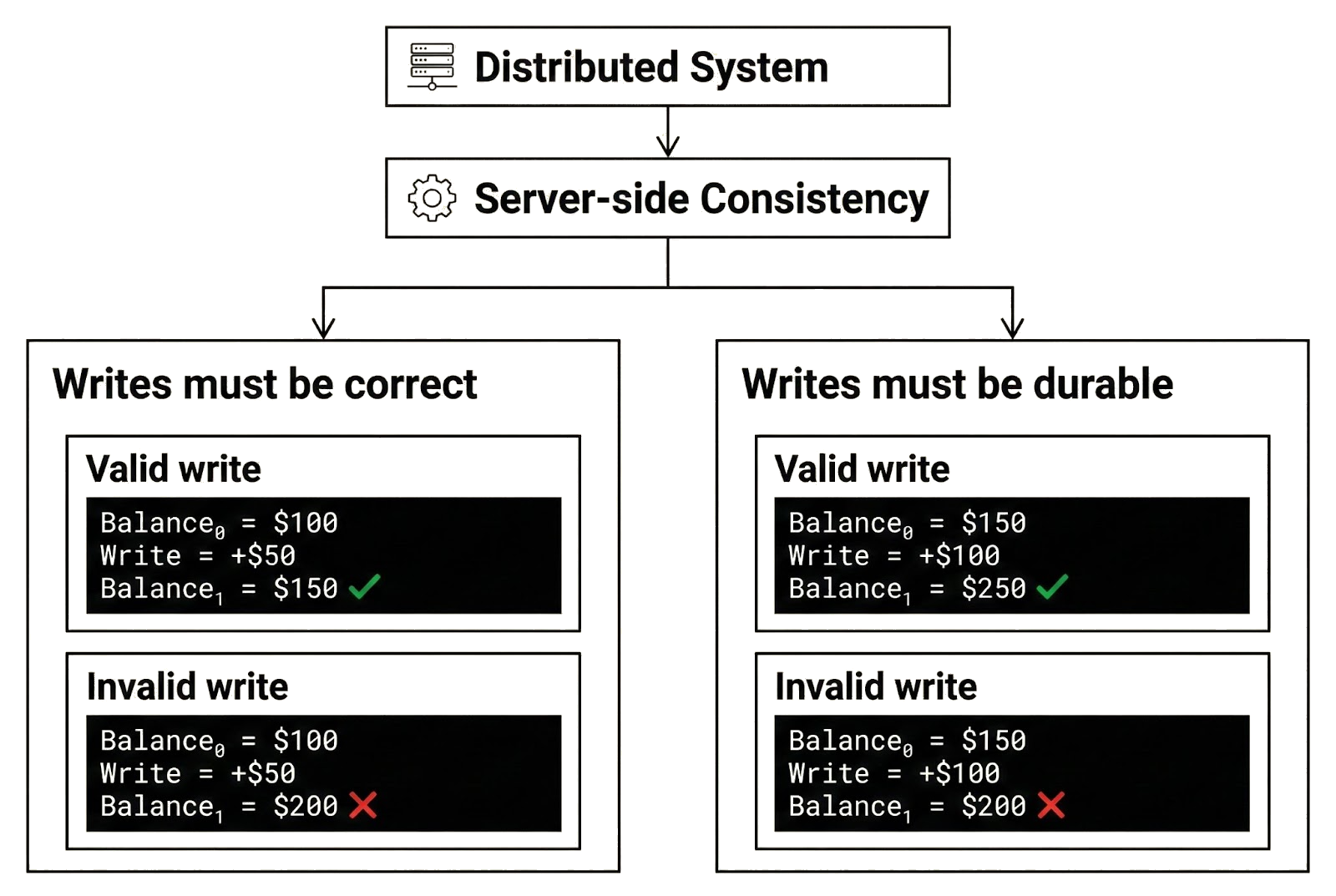
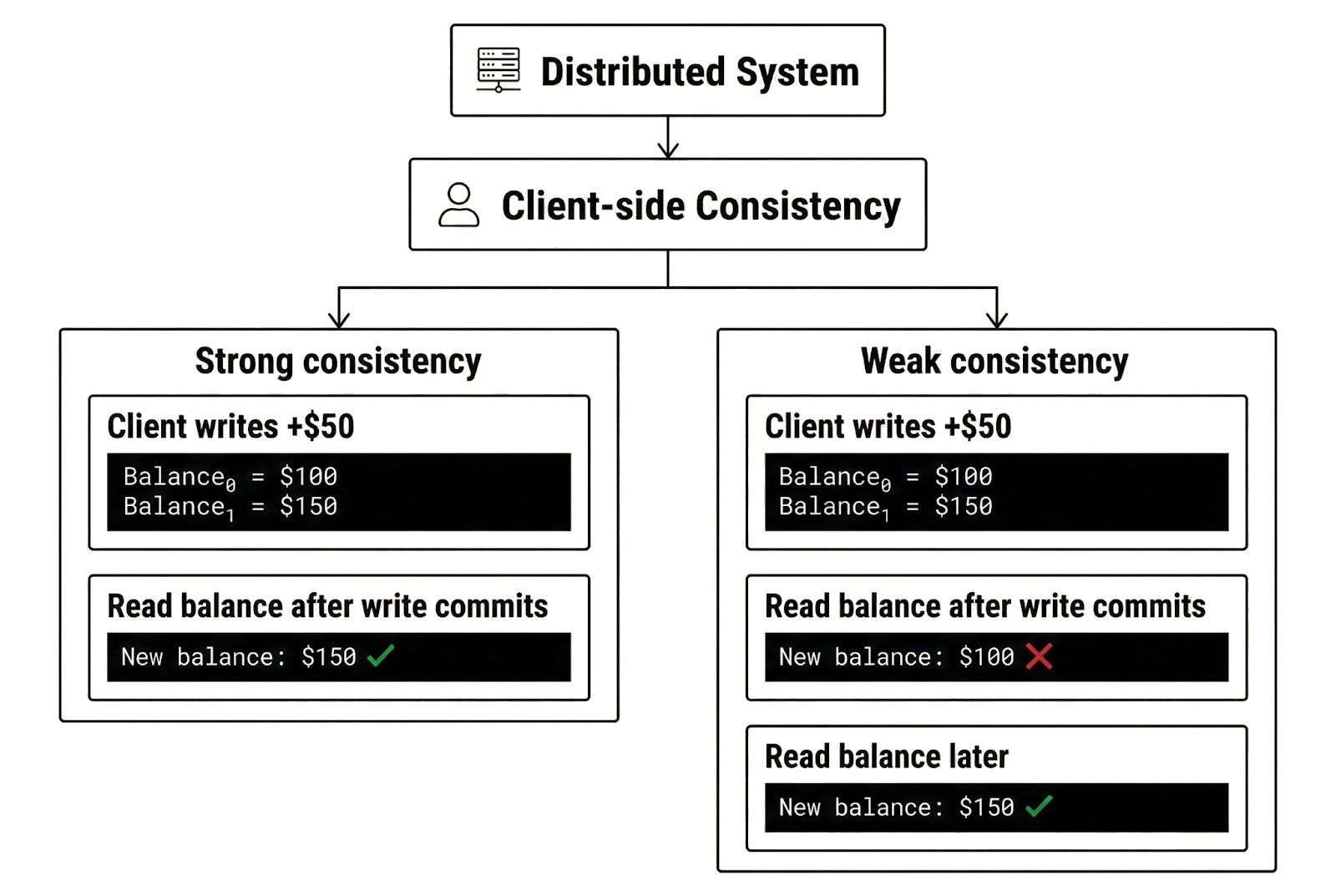
Client-side consistency, by contrast, concerns the visibility and ordering of committed writes from a client's perspective. It determines when a client can observe committed writes, whether reads reflect the latest committed state, and the consistency guarantees for those reads over time.
Strong client-side consistency means Alice sees the updated balance immediately after her deposit commits, and all subsequent reads reflect the latest committed write. Weak client-side consistency means Alice may not see the update immediately, and later reads may return stale data that does not reflect her most recent committed write. When we refer to “consistency” in this article, we are referring to client-side consistency unless specified otherwise.
How consistency works in practice
Imagine Alice’s bank is designed as a distributed system. It maintains a database that stores customer information, account balances, and other data, and replicates it across multiple servers in different regions. By distributing data storage rather than relying on a centralized database server, the bank improves reliability, availability, and fault tolerance. If outages affect replicas in one region, clients can connect to replicas in unaffected regions to continue processing transactions. The system does not halt when individual replicas malfunction.
Replication can also improve scalability and reduce latency. The bank can scale horizontally by dividing the database into shards and assigning different groups of replicas to manage each shard, allowing the system to process transactions in parallel. Transactions that touch a particular shard are handled only by the replicas responsible for that shard rather than by all replicas, increasing overall throughput. To reduce latency, the bank may deploy replicas in regions where most users are located. Because geographic distance affects message delays, users experience fewer delays when communicating with nearby replicas than with replicas in distant regions.
In this example, the bank operates replicas in New York, San Francisco, and Texas. Each replica stores a copy of the bank’s data and processes user transactions. Users interact with the system through endpoints that connect to replicas. An endpoint receives a client’s transaction, forwards it to a replica, waits for the replica to process it, and returns the result to the client. Alice interacts with the bank through three endpoints: the local branch, a nearby ATM, and the bank’s mobile application.
Transactions processed by replicas either read or write data. Writes modify the database state by updating stored values. Reads return previously committed data without changing state. Alice performs a write when she makes a deposit or withdrawal and performs a read when she checks her balance. Deposits and withdrawals change the account balance and therefore update the database state, while a balance check only observes the result of previously committed writes. Server-side consistency ensures that every stored balance reflects a valid, committed write.
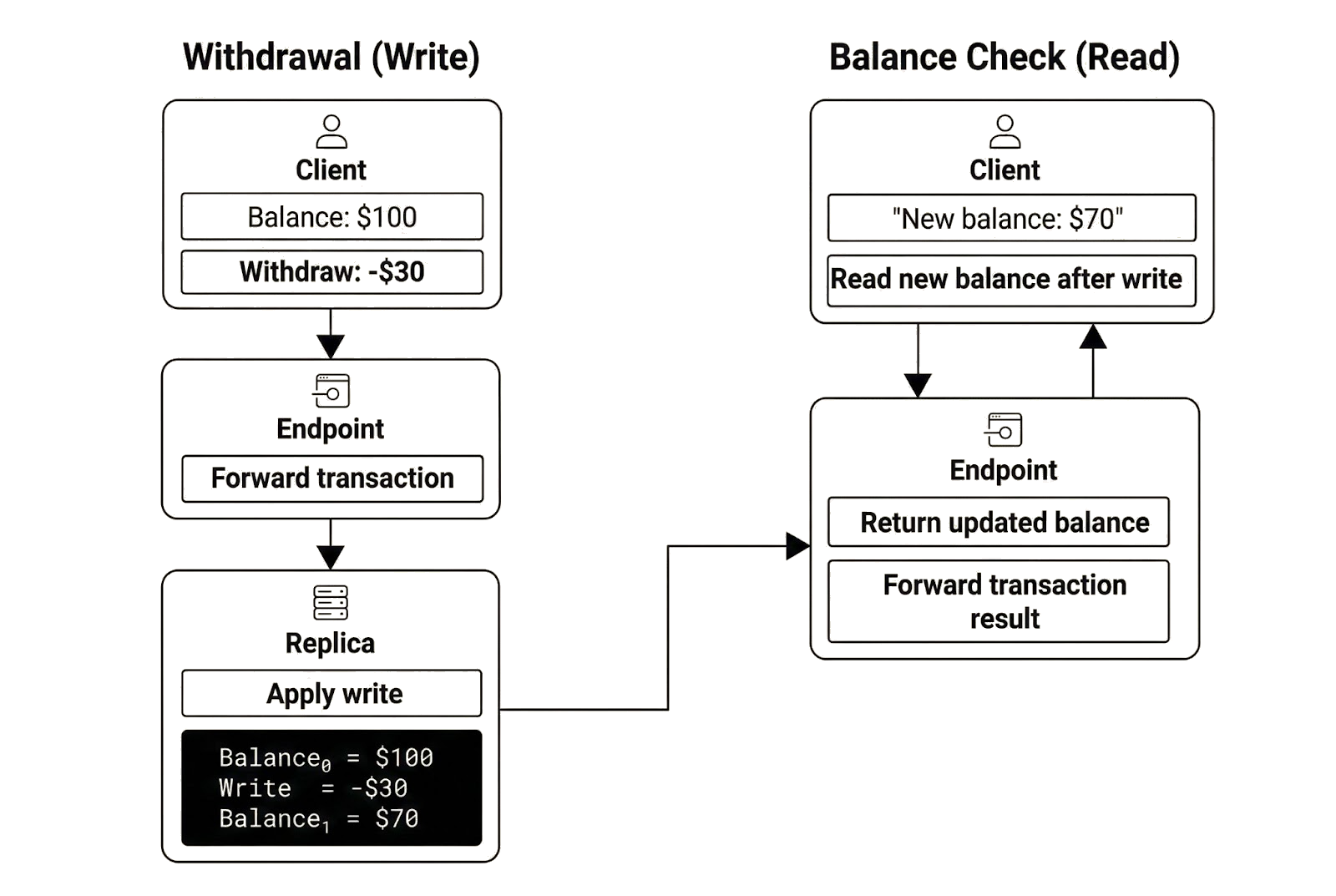
To maintain agreement across replicas, writes must be propagated. After a replica processes and commits a write locally, it broadcasts that write to other replicas. Those replicas validate and apply the write to their local copies of the database, then commit the updated state. Once all replicas have applied the write, they store the same state.
This architecture provides the benefits of replication, but it also introduces consistency challenges. Consider the earlier example in which Alice has $100 in her account and deposits $50, committing a write that changes her balance from $100 to $150.
In this scenario, Alice completes the deposit at the local branch and confirms her balance is $150. However, when she walks to a nearby ATM and checks her balance, she sees the old balance of $100. Logging into the mobile application returns the same stale balance. The update has not yet propagated everywhere, so her reads do not reflect the latest committed state.
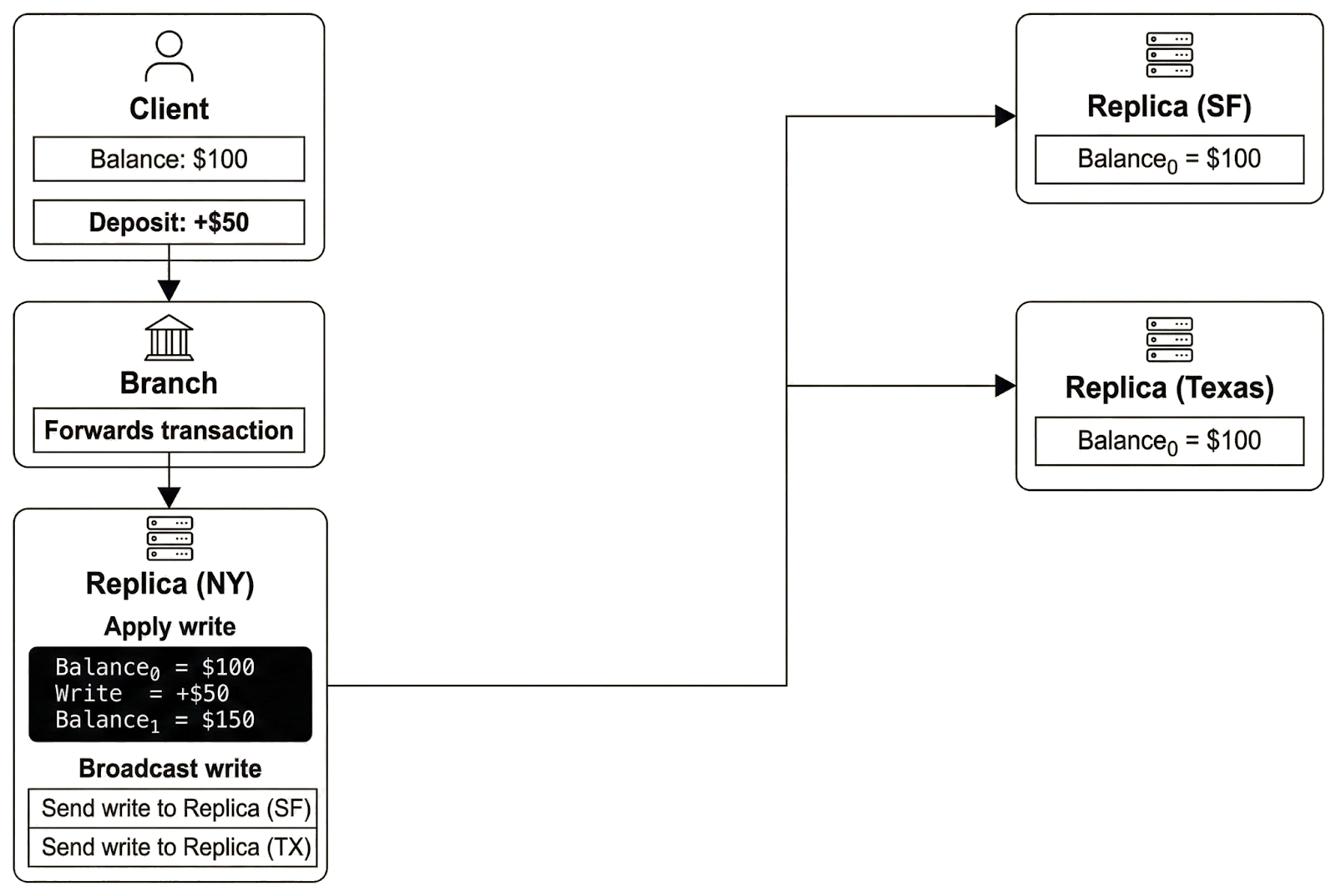
Alice sees different balances because each endpoint connects to a replica that may or may not have received and applied the latest committed write. Messages sent from New York to Texas or San Francisco take time to reach their destinations. During that interval, the New York replica reflects the updated balance while the others still store the earlier state.
During this propagation window, replicas temporarily hold different versions of the same data, so a client connected to different replicas may observe different states when performing reads. In Alice’s case, the branch replica returns $150 because it has processed the committed write, while the ATM replica returns $100 because it has not yet applied the update. Her reads provide no guarantee that they reflect the latest committed state.
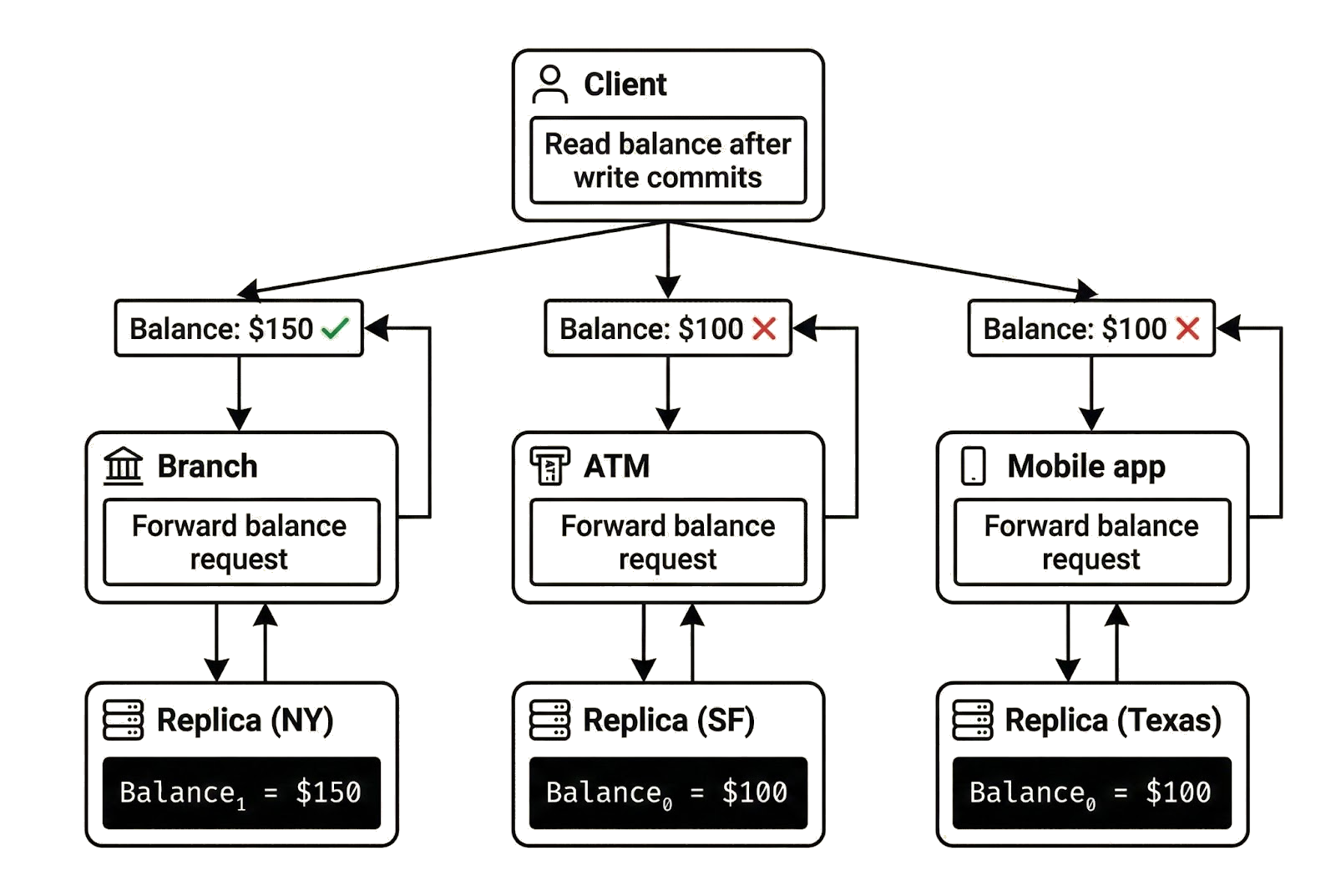
A system with strong consistency prevents this outcome by ensuring every read reflects the latest committed write, regardless of which replica serves the request. Once Alice’s deposit commits, all replicas must return $150. Strong consistency guarantees that clients observe a single, up-to-date view of state.
Not all systems enforce this guarantee. Some applications tolerate stale data if delays are bounded. Others require narrower properties, such as ensuring reads never move backward in time or ensuring clients always see their own committed writes.
Consistency levels allow developers to select guarantees that match application requirements rather than relying on a single uniform model. The next section introduces six common consistency guarantees: strong consistency, bounded staleness, consistent prefix, monotonic reads, read-my-writes, and eventual consistency.
Strong consistency
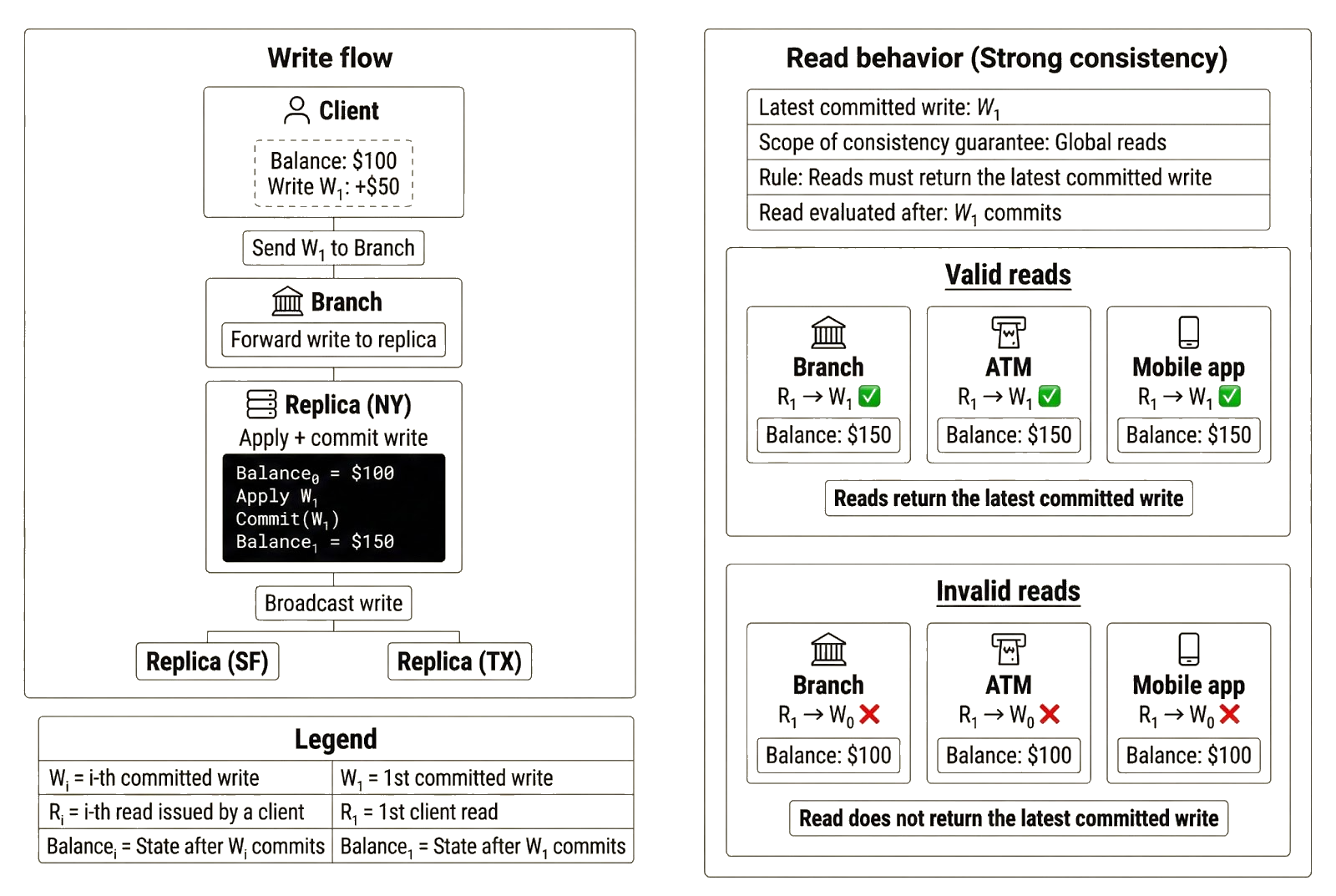
Strong consistency is the strongest consistency guarantee a distributed system can provide to clients. Under strong consistency, every read returns the most recently committed write. From the client’s perspective, the system behaves as if there were a single authoritative copy of state, even though the data is physically replicated across multiple nodes.

Earlier, we said that replication makes consistency difficult because replicas receive and apply updates at different times. Strong consistency addresses that problem. It ensures clients observe the same state regardless of when replicas receive and apply updates internally. Achieving this usually requires coordination. The system may require replicas to acknowledge a write before committing, or require replicas to fetch missing updates from peers before serving reads. In exchange for the coordination overhead and added latency, strong consistency ensures clients always read fresh data and observe the same state across replicas.
To illustrate, Alice deposits $50 at the branch when her balance is $100. Once the branch finalizes Alice’s deposit (i.e., the replica serving the branch commits the write), she should see the update reflected everywhere. If she later checks her balance at the branch, ATM, or mobile app, the replica serving that read must reflect the committed write and return $150. It is inconsequential whether the branch replica applied the write first or if other replicas have yet to observe it.
To be clear, geographical distance affects the speed at which replicas receive and apply writes. If a replica has not observed the latest write, its view of state will not reflect the updated balance in the account. Strong consistency works around this by requiring lagging replicas to delay processing Alice’s request until they have observed the latest committed write and can serve fresh data.
From Alice’s perspective, an endpoint that delays responding appears temporarily unavailable. But this unavailability is temporary and downstream of the consistency model’s requirement. Once a replica has observed the latest committed write, it can safely resume serving reads. As a result, reads may be delayed, but they never return stale data or conflicting states.
Linearizability vs. serializability
Strong consistency is also known as linearizability. A system is linearizable if operations appear to take effect in a single global order that respects real-time completion. If one operation completes before another begins, every client must observe them in that order. Linearizability, therefore, constrains what results clients are allowed to observe and the order in which completed operations may appear.
Linearizability should not be confused with serializability. Serializability is a property of transaction execution: it guarantees that the outcome of executing transactions concurrently is equivalent to executing those transactions in some valid sequential order. Linearizability is a property of what clients observe: it guarantees that operations are observed in real-time order.
Serializability constrains how transactions execute and requires that the resulting state reflect some valid sequential history. Linearizability constrains what clients are allowed to observe and requires that this history also respects real-time order. The difference becomes clearer in the bank example.
Suppose Alice deposits $50 into her account when her balance is $100. After the system confirms that the deposit has completed, Alice checks her balance. There are two possible serial orders for a deposit transaction and a read transaction that both access the same account:
- Read → Deposit
- Deposit → Read
Under serializability, either ordering is valid as long as the result corresponds to one of those sequential executions. If a replica executes the read before the deposit internally, returning $100 is consistent with the serial order Read → Deposit. From an execution standpoint, the system is correct because the result reflects a valid serial history.
Linearizability adds an additional constraint. If the deposit is completed before the read begins, the system must order them accordingly. Once Alice receives confirmation that the deposit has completed, any subsequent read must reflect that write. Returning $100 would violate linearizability because it contradicts the real-time order of operations.
Enforcing this guarantee requires coordination to ensure that replicas respect the real-time order of committed writes when serving reads. Once a write is acknowledged as committed, replicas must ensure that no subsequent read is served from a state that predates that commit. This may require replicas to block reads, forward them to a leader, or synchronize with peers before responding.
This is similar to what we described earlier, where replicas delay or reroute reads to avoid serving stale data. However, linearizability imposes a stronger requirement: reads must not only reflect the latest committed state, but must also preserve real-time order. If a write completes before a read begins, that read must reflect it.
Applications of strong consistency
Strong consistency is critical in systems where stale reads can lead to incorrect decisions. In a banking system, if Alice deposits money and then immediately initiates a withdrawal or transfer, the system must evaluate her balance against the latest committed state. Returning an outdated balance could allow an overdraft or incorrectly reject a valid transaction. A system that permits stale reads after a completed write risks making decisions based on a state that no longer exists in real time. Strong consistency prevents this class of correctness failures by ensuring that completed writes are immediately and globally visible.
Other systems where strong consistency is preferred include:
- Consensus protocols: All validators must agree on the same committed state before advancing to the next block.
- Payment processors: Customers must not be charged twice or allowed to double-spend funds.
- Settlement layers and clearinghouses: Finalized transfers must be reflected consistently across all participants before new transactions are processed.
- Exchanges and trading platforms: Order books must reflect the latest trades.
- Identity and access management (IAM) systems: Credential revocations and access authorizations must take effect immediately.
- Inventory tracking systems: The final unit of stock must not be sold twice.
What guarantees does strong consistency provide?
The examples above illustrate the guarantees provided by strong consistency:
- Reads reflect the latest committed write: Every read returns the updated state after a committed write. In the bank example, once Alice’s deposit completes, she sees the updated balance ($150) on all subsequent reads.
- All clients observe the same state: Clients connecting to different replicas observe the same committed state. The local branch, ATM, and mobile app may be served by different replicas, but they all return $150 once the deposit is finalized.
- No stale reads after commitment: Once a write is committed, the old state is no longer observable. In the bank example, none of the endpoints can return the earlier balance of $100 after the deposit completes without violating strong consistency.
Limitations of strong consistency
- Higher latency and reduced availability: If a replica has not yet applied an update, it cannot safely return the old value. The system must either delay the read or ensure that the request is handled by a replica that reflects the latest committed state.
- Requires coordination: Replicas must agree on a single, committed order of operations before exposing results to clients. This coordination can increase response time and reduce fault tolerance under network partitions.
Bounded staleness
Bounded staleness guarantees that clients never read stale data beyond a predefined limit. Reads may return values that lag the most recently committed write, but only within a configured bound. That bound can be defined in terms of time (e.g., T time units behind the latest write), versions (e.g., at most K committed updates behind), or another measurable constraint.

A client may not observe the latest committed state, but it will never observe a state that lags the most recent write by an arbitrary margin. Because replicas rarely apply updates simultaneously, temporary divergence is inevitable. As replicas catch up and process new writes, reads eventually reflect more recently committed states within the defined bound. Bounded staleness allows temporary divergence, but limits how far replicas can fall behind.

This idea becomes easier to understand if we revisit the bank example, in which Alice deposits $50 into an account that previously held $100. Under bounded staleness, Alice may not immediately see $150 when she checks her balance, but the updated balance must be visible after a certain point because the system constrains how stale reads can be.
The system might use a time bound with T = 2 minutes, meaning that reads are at most two minutes behind the latest write. If Alice completes the deposit at 10:00 and checks her balance at 10:01, a replica may return $100 if it has not yet processed the deposit. This is allowed: the data is stale, but it lags the most recent update by no more than two minutes. After 10:02, however, every replica must return $150. A $100 read beyond that point would violate the bounded staleness guarantee because the staleness exceeds the configured time bound.
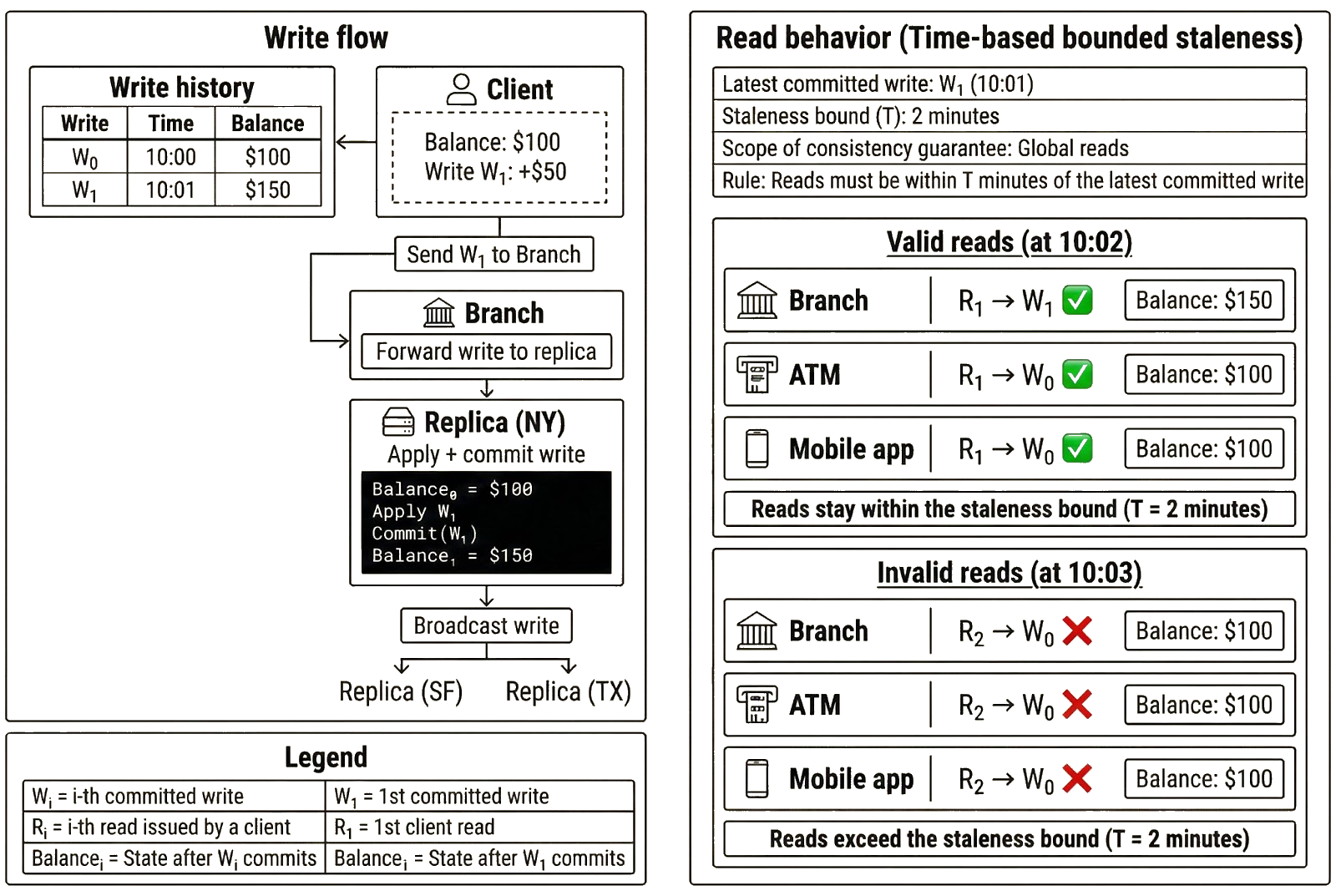
The system could also use a version bound, where K = 1, meaning that reads are at most one committed update behind the latest committed version. Imagine Alice’s deposit creates a new version of state (“v2”) distinct from the old version (“v1”). A lagging replica that has not seen Alice’s update and is still on v1 may return $100. However, once another update commits and creates a new version (“v3”), that replica must return at least v2 on the next read. Returning v1 would violate the bounded staleness guarantee because the read would lag the latest committed state by more than one version.
Applications of bounded staleness
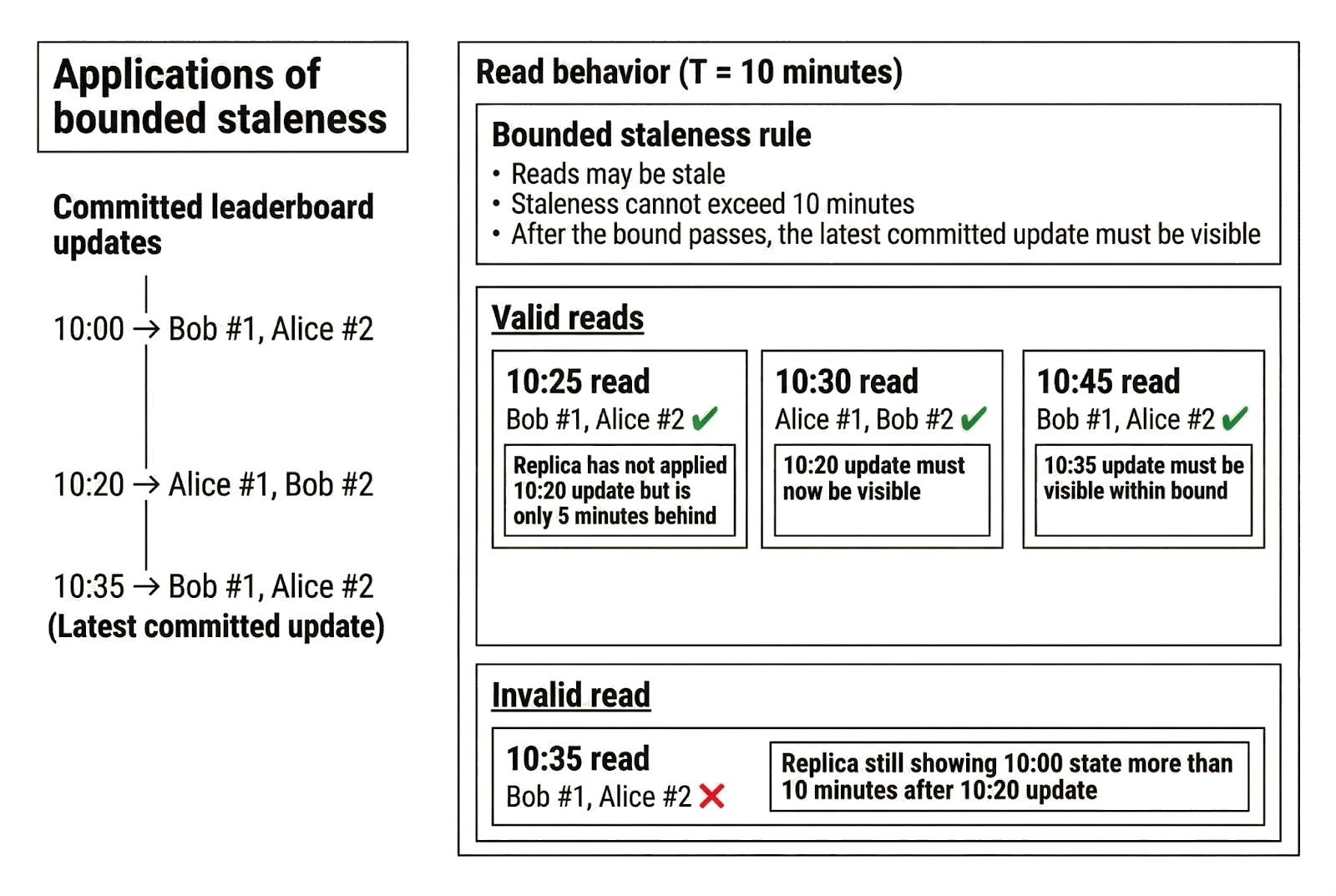
Leaderboards are a concrete application of bounded staleness. Suppose a game guarantees that the rankings displayed are at most 10 minutes behind the latest write. Clients connect to different servers to read the leaderboard, which is hosted on a geo-replicated system, and may see different rankings depending on whether the server has applied recent updates. The guarantee ensures that the rankings observed by any client are never older than the configured bound (10 minutes).
Consider the following timeline of updates to the leaderboard:
- 10:00: Bob is No. 1 and Alice is No. 2
- 10:20: Alice wins and overtakes Bob
- 10:35: Bob wins again and returns to No. 1
Bob’s 10:25 read is stale because the replica serving the read has not yet applied the 10:20 update, but it is only five minutes behind and therefore within the 10-minute bound. By 10:30, the 10:20 update must be visible. Likewise, by 10:45, the 10:35 update must be reflected. The leaderboard may temporarily show different rankings to different clients, but it cannot show results that fall outside the defined window, and reads eventually reflect the most recent committed updates within that bound.
Bounded staleness is useful in scenarios where a system can tolerate slightly weaker guarantees of data freshness:
- Analytics systems with SLAs: Reports must be no more than a fixed number of minutes or updates behind the latest write.
- Geographically replicated databases: Regional replicas may lag the primary node, but only within a defined time or version bound.
- Global social media feeds: Updates may propagate with a slight delay, but are guaranteed to appear within a defined time window.
- Content delivery networks (CDNs): Cached content may be slightly stale, but invalidation policies or TTL values bound how long outdated content can be served.
- Search indexing systems: Newly updated documents may not appear immediately, but the indexing delay is bounded.
What guarantees does bounded staleness provide?
The bank and leaderboard examples illustrate the core guarantees of bounded staleness:
- Bounded lag time: Reads may lag the latest write, but only up to a predefined upper bound. Alice may briefly see $100 (instead of $150) after depositing $50, but only within the configured window. Likewise, leaderboard rankings may temporarily reflect outdated positions, but never beyond the allowed bound.
- Predictable freshness: Because the system defines the bound in advance, clients can reason about how fresh their reads are. Alice knows her balance will never be more than one update or two minutes behind. Players know rankings will never be more than ten minutes out of date. Even if replicas are not perfectly synchronized, there is a clear limit to divergence.
- Configurable consistency: The staleness bound itself is configurable. A financial application might require a very small staleness window, while a public leaderboard can tolerate a larger one. The specific bound changes, but the structure of the consistency guarantee remains the same.
Limitations of bounded staleness
- Slightly stale reads: Different clients may observe different states at the same moment. Bob and Alice can disagree about leaderboard rankings, and two replicas may temporarily disagree about Alice’s balance. Conflicting reads are allowed as long as they remain within the configured bound.
- No real-time guarantee: Bounded staleness limits how stale reads can be, but it does not guarantee that every read reflects the most recently committed write. Replicas can temporarily diverge and return different values. If clients require immediate, real-time visibility of updates, bounded staleness is insufficient.
Consistent prefix
Consistent prefix guarantees that clients observe a valid, ordered sequence of writes starting from the first committed update. Reads may be stale, but the returned results always respect the order in which writes were committed. The term “consistent prefix” reflects a key property of this model: each replica exposes the same ordered history of writes, but it may be at a different point in that history.
A prefix simply means the history from the beginning up to some point in the global write order. Replicas may be at different positions in that order, but they share the same starting point and derive state from the same ordered sequence of committed writes. The difference lies in how far each replica has progressed along that history.

Unlike the shared prefix, the progress of a replica is not required to be identical across replicas. A replica that has processed more writes will reflect a more recent state. A replica that has processed fewer writes may return stale data. You can think of this difference as the “suffix” of the write history: where each replica currently sits in the ordered sequence of committed writes may vary. What must remain consistent is the prefix, meaning the ordered history from the beginning up to whatever point that replica has reached.
Let’s revisit the bank example to illustrate this guarantee. Suppose Alice’s initial balance was $0. She deposits $25 four times, bringing the balance to $100, and then makes a final deposit of $50 to reach $150. The canonical ordering of committed writes is:
- $0
- $25
- $50
- $75
- $100
- $150
Under consistent prefix, replicas may return $0, $25, $50, $75, $100, or $150 as the balance. Except for $150, these values are potentially stale. However, each read is valid because it reflects a state that appears in the history from the beginning up to a specific write. Even $0 is valid, since it represents the initial state before any deposits occurred.
Suppose the branch where Alice completed the deposit shows $150, but she sees $100 in the mobile app and $75 at the ATM. Even though $100 and $75 are stale relative to $150, the mobile app and ATM replicas still comply with consistent-prefix rules. The mobile app has processed the first four deposits but not the final one. The returned value of $100 is a valid prefix of the committed write history and reflects the following ordered sequence:
- $0 → $25
- $25 → $50
- $50 → $75
- $75 → $100
Meanwhile, the ATM has processed the first three deposits, but not the last two. The returned value of $75 is also a valid prefix of the write history and reflects the following ordered sequence:
- $0 → $25
- $25 → $50
- $50 → $75
Consistent prefix does not guarantee that replicas return the latest state. It does guarantee that each replica’s state is derived from processing committed writes in the same order. In this case, the San Francisco replica returned $75 after applying the first three writes, while the Texas replica returned $100 after applying the first four writes in Alice’s committed write sequence. The New York replica has processed the most recent write ($100 → $150), but all replicas started from the same point in history ($0) and followed the same ordered sequence, even though the New York replica (which serves the branch) has progressed further along that sequence.
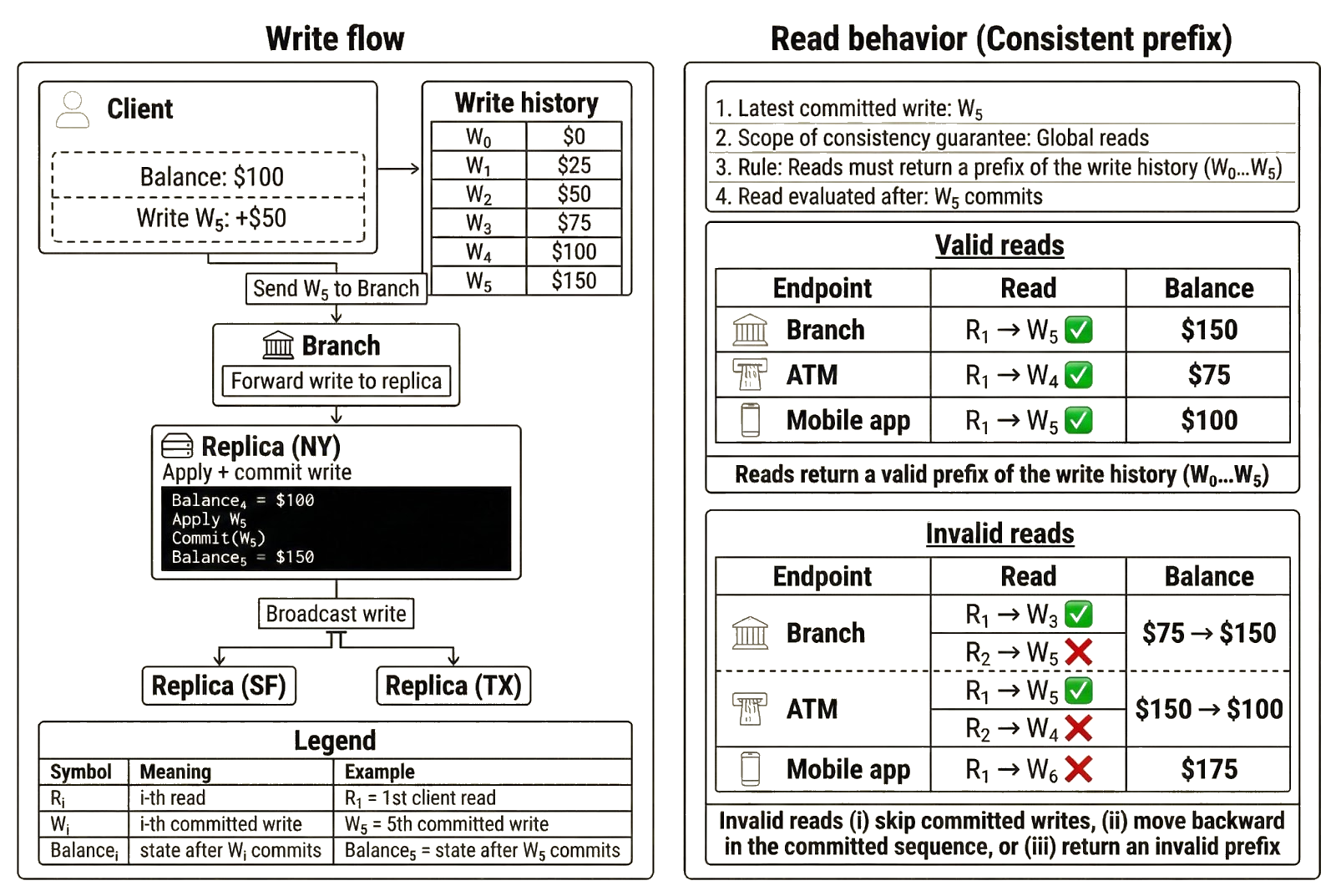
A replica violates consistent prefix if it does any of the following:
- Skip committed writes: If a replica returns $150, it must have processed the preceding writes that produced $25, $50, $75, and $100. Returning $150 without those intermediate updates would mean the state was not derived from the ordered history.
- Move backward in the sequence: If a replica returns $100 and later returns $75 for the same account without any new writes occurring, it has moved backward in the write order. Under consistent prefix, replicas advance along the same ordered sequence of committed writes; they do not reverse direction. Returning $75 would only be valid if a new committed write, such as a withdrawal, produced that balance.
- Return an invalid state: Returning $120 would violate consistent prefix because no committed write ever produced that balance. The state would not align with the actual sequence of updates.
Applications of consistent prefix
Event streams provide a real-world example of consistent prefix consistency guarantees. Consider an e-commerce system that records state changes as an ordered stream of events:
- OrderCreated
- PaymentReceived
- OrderShipped
Each event is appended in a fixed order, and replicas process the stream over time. Under consistent prefix, replicas may be at different positions in this stream. One replica may have processed only OrderCreated, another may have processed OrderCreated and PaymentReceived, and a third may have processed all three events. As a result:
- A client may see an order that exists but has not yet been paid for.
- A client may see an order that has been paid but not yet shipped.
- A client may see the full lifecycle of the order.
All of these observations are valid because they reflect the event history from the beginning up to some point in the sequence. What is not allowed is observing events out of order. A replica cannot return OrderShipped unless it has already processed OrderCreated and PaymentReceived. Every read must align with the order in which events were committed.
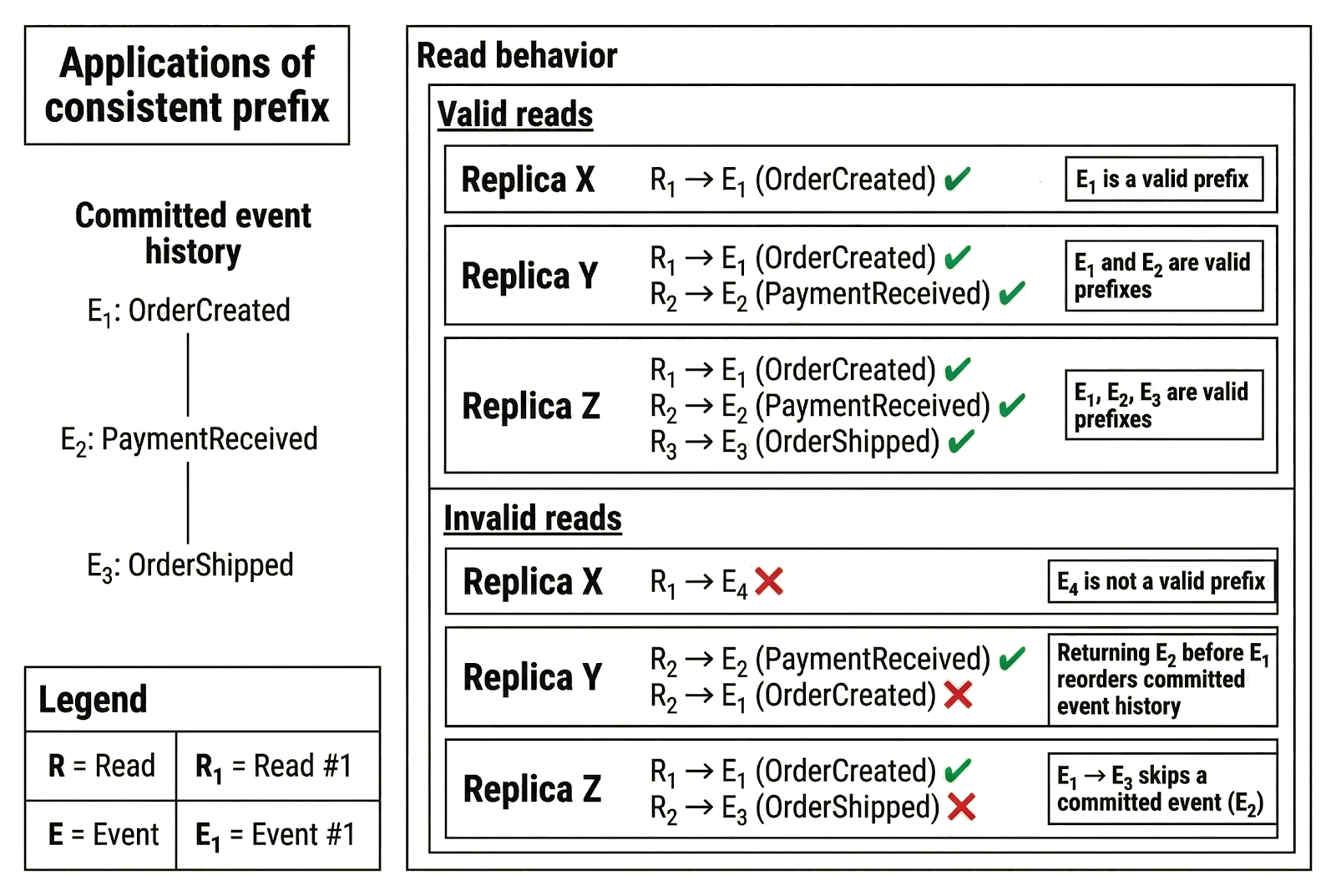
Other applications that rely on consistent prefix-style guarantees include systems where state evolves as an ordered, append-only history:
- Activity feeds: Posts and updates must appear in chronological order, even if the latest items have not yet propagated.
- Messaging systems: Messages within a conversation must appear in the order they were sent.
- Audit logs: Entries must appear in the order they were recorded.
- File versioning systems: Edits must appear in the order they were applied.
- Event sourcing systems: Events must be processed in the order they were appended to the log.
- Public blockchains: A node may lag the head of the chain, but it cannot present block N without presenting blocks 1 through N-1.
What guarantees does consistent prefix provide?
The examples above illustrate the guarantees that consistent prefix provides:
- Reads respect global write order: Replicas preserve the canonical ordering of committed writes. In the bank example, a replica cannot expose the final $150 balance unless it has already applied the earlier deposits. In the event stream, a replica cannot expose OrderShipped without first exposing OrderCreated and PaymentReceived.
- No gaps in observed history: Clients never observe a state that skips intermediate updates. Every returned state must reflect a contiguous progression through the write sequence. Seeing $100 without the prior deposits that led to it would violate this guarantee. Observing OrderShipped without earlier events would introduce a gap in the event history.
- Every read corresponds to a valid prefix: Each returned value reflects a state that actually existed in the ordered history of writes. A replica may stop at $100 or $150 in the bank deposit timeline, or at PaymentReceived in the event stream, but each reflects a legitimate point along the same sequence of committed updates.
Limitations of consistent prefix
Consistent prefix permits certain anomalies:
- Reads may return older states: A replica may return a state that does not include the most recent committed writes. In the bank example, Alice may see $100 at the ATM even though the branch shows $150. In the event stream example, a client may see PaymentReceived but not yet OrderShipped. The state respects write ordering, but it may be stale.
- Clients may observe different states: Two clients may read from replicas that have progressed to different points in the write sequence. For example, Alice may observe $100 at the ATM while the branch shows $150. In the event stream example, one replica may expose PaymentReceived while another has already processed OrderShipped, causing connected clients to see different statuses for the same order.
Monotonic reads
Monotonic reads are a consistency guarantee that applies to a sequence of read operations performed by a client. Under monotonic reads, a client’s view of committed writes only moves forward. Once a replica returns a value produced by a committed write, future reads in the same session cannot return a value from an earlier write. Initial reads may be stale, but the client will not “travel backward” in the write history as it continues reading.
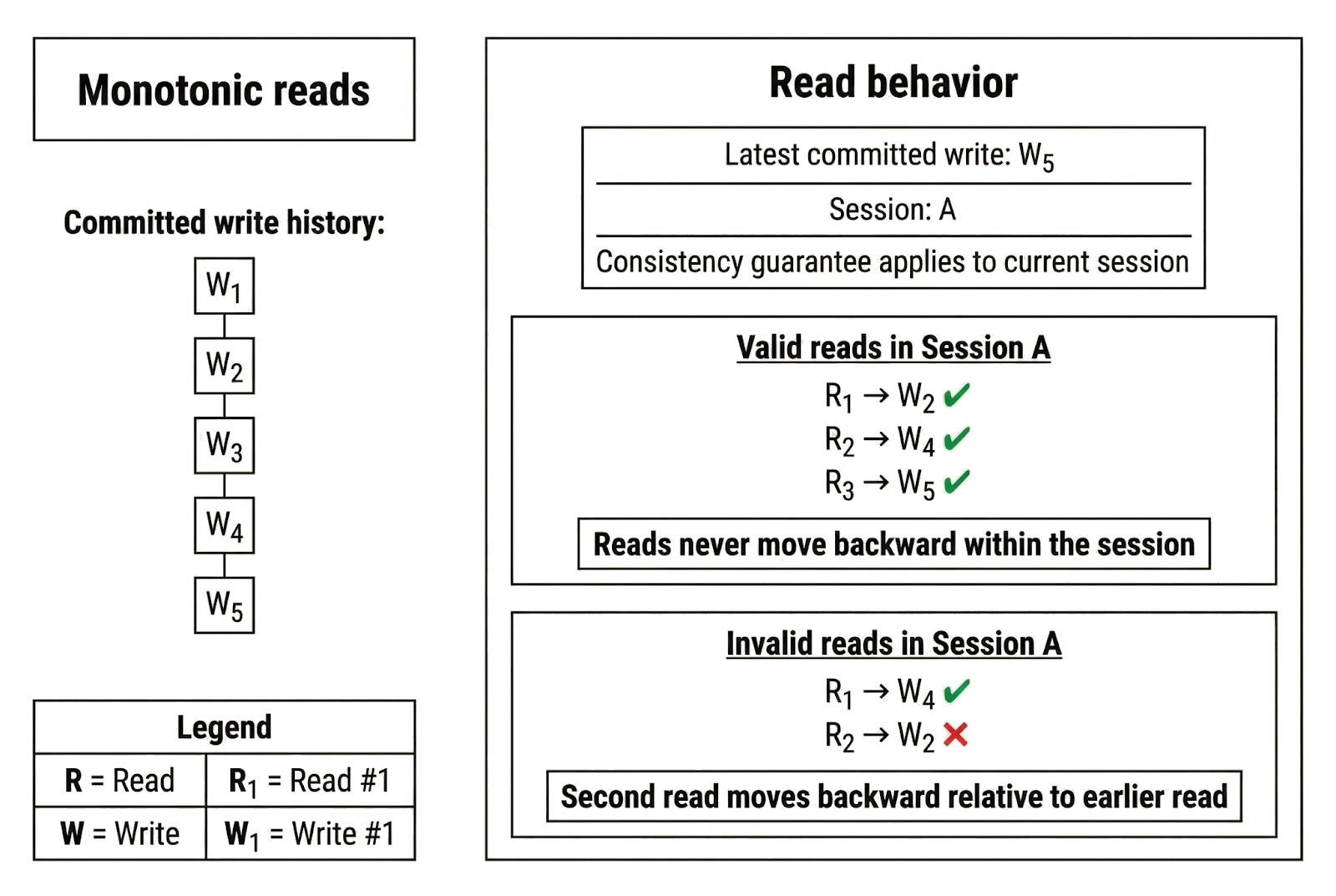
In some production systems, monotonic reads are treated as a session-level guarantee and enforced using session tokens. A replica issues a token when a client first connects, and the token anchors the client’s minimum visible position in the write history. The replica does not need to serve the latest write at the start of the session, but it must not return anything older than what it has already shown that client. As replicas catch up and the client performs additional reads, the returned values may move forward through the write history, even if intermediate updates are skipped.
To illustrate, imagine a database that stores a single letter and updates it whenever a write occurs. Suppose the most recent committed value is “Z.” A client connects to a lagging replica, and its first read returns “K.” On a later read, the replica returns “M,” and later still it returns “Z.” The reads were stale at first and skipped intermediate values, but they never moved backward. The client never saw “J” after seeing “K.” You might not see the latest write immediately, but your session’s view does not regress.
The guarantee is session-scoped. If the client switches replicas, the next read may return an older value if the new replica is further behind. In the earlier example, the client could read “Z” from one replica and later read “R” from another replica that has not caught up. Monotonic reads then apply within the new session: after the first read from the second replica returns “R,” that replica must not return anything older than “R” during that session. As the replica catches up, subsequent reads may move forward and eventually converge with what the first replica already showed.
We can tie the same idea back to the bank example. Recall that the bank runs multiple geo-replicated servers, and the endpoints Alice consults to read her balance (local branch, mobile app, and ATM) are served by different replicas. Because replicas apply writes at different times, Alice may not immediately see the latest balance when connected to an endpoint served by a lagging replica.
For example:
- The cashier processes the deposit and shows Alice a balance of $150.
- Alice later tries to withdraw $150 at the ATM, but the withdrawal fails because the ATM still sees a balance of $100.
- She opens the bank app, and it shows $100 as well.
These stale reads are permitted under monotonic reads. What is not permitted is moving backward. For instance, after the ATM shows Alice $100, it should not later show a lower balance unless a new withdrawal has actually been committed. If the replica serving the ATM has not yet applied the $100 → $150 update, it may continue returning $100, but it cannot return a value produced by an earlier committed write. Once it does return $150, future reads in that session cannot revert to $100. The same principle applies when Alice reads her balance through the mobile app.
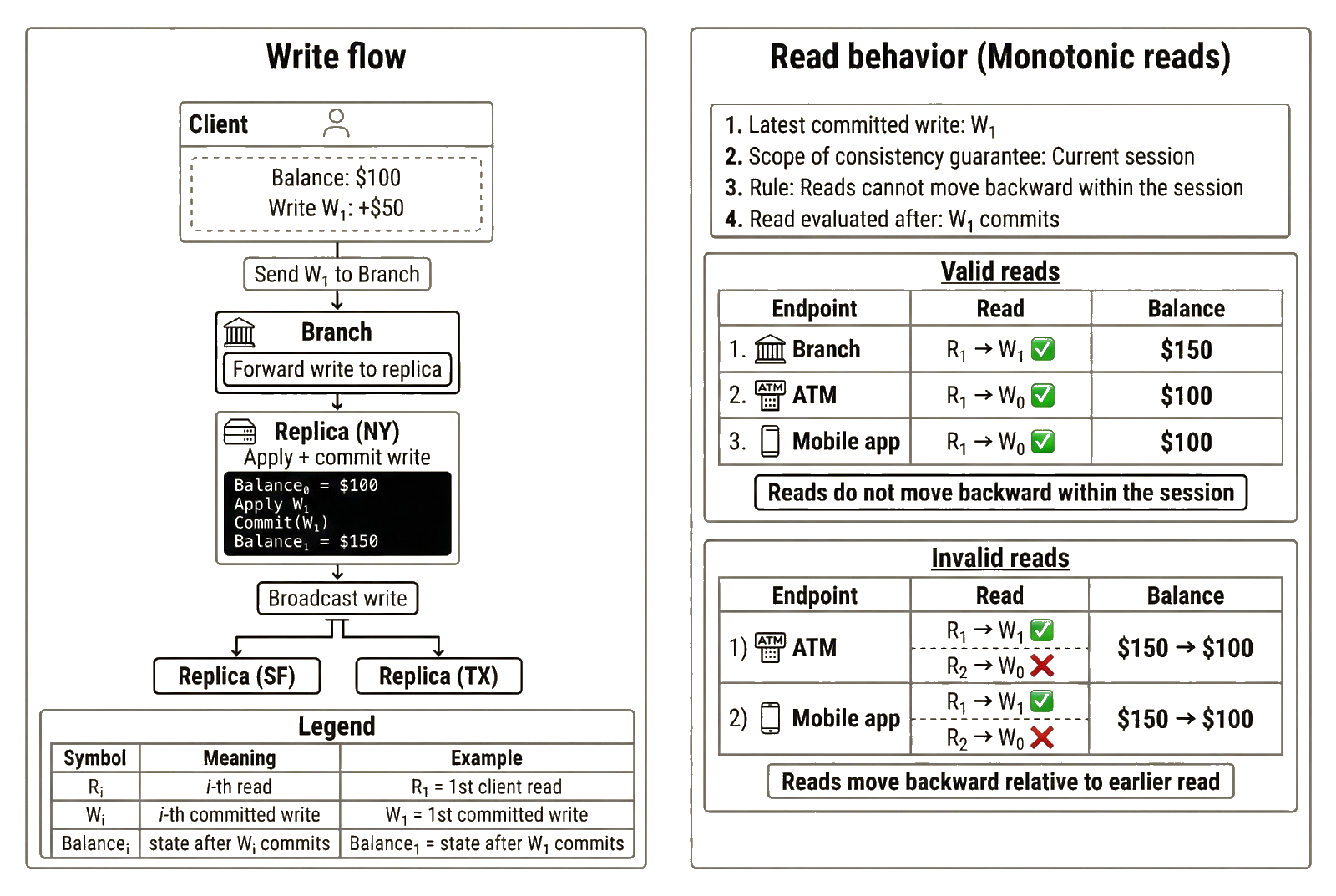
Applications of monotonic reads
User sessions in software applications are a common use case for monotonic reads. When a user logs in, the system typically creates a logical session and tracks it with a session identifier. If Alice stays logged into the bank app and keeps refreshing, the app should not bounce between older and newer balances. It may start at $100 and eventually show $150 as the replica catches up, but it should not move backward unless a real update changes the balance.
The same pattern appears in other systems that rely on monotonic reads. In each case, a client’s view must move forward during a session and never regress once a value has been observed:
- Geo-replicated databases with session consistency: A session token records the latest version a client has seen, and the replica must not return a version older than the one encoded in that token while the session remains active.
- Online games (player progress): Player progress must not revert to an earlier level or score during an active session unless a new in-game event (e.g., a penalty or reset) changes it.
- Search engines (paginated queries): Secondary pages must not be generated from an index state older than the one used for earlier pages in that session while a user is paging through results.
- Media streaming playback: Once a playback position has been recorded during a session, subsequent reads must not return a timestamp earlier than that position unless the user intentionally rewinds.
What guarantees do monotonic reads provide?
The previous examples illustrate the core guarantees of monotonic reads:
- Reads never travel back in time: Once a client has observed a value produced by a committed write, subsequent reads in that session cannot return a value from an earlier write. In the bank example, if Alice sees a balance of $100 on the ATM, she must not later see a lower balance unless a new withdrawal is committed. In the session-token example, once a client has observed version 42, the replica cannot return version 41 during that session.
- Per-session ordering: The monotonic guarantee applies within a single session. Each session maintains its own forward-moving view of the write history. In the bank example, the ATM session and the mobile app session may start from different balances if they connect to different replicas, but within each session, once a balance has been observed, subsequent reads cannot return an earlier one.
- No forced freshness at session start: The first read in a session may be stale. Monotonic reads do not require replicas to return the latest committed write when a session begins; they only require that the client’s view does not move backward once it has observed a value.
Limitations of monotonic reads
Monotonic reads also have limitations:
- Initial reads may be stale: The first read in a session may lag behind the latest committed write. In the alphabet example, the client may begin at “K” even though the latest value is “Z.” In the bank scenario, Alice may initially see $100 even though the balance is already $150 elsewhere. Monotonic reads do not guarantee freshness at session start.
- Different clients may see different states: Two clients connected to different replicas may observe different values at the same moment. One client may have progressed to “Z,” while another is still at “M.” In the bank example, one client may see $150 while another sees $100. The guarantee ensures that each client’s view moves forward, not that all clients share the same view.
- Consistency guarantees reset with a new session: The forward-only rule applies within a single session. If a client reconnects or starts a new session, it may observe a value older than one it previously saw. A client that reached “Z” in one session may begin at “R” in a new one if it connects to a lagging replica. Likewise, Alice’s ATM and mobile app sessions may start from different balances, even though neither session can move backward once it begins.
Read-my-writes
Read-my-writes is a consistency guarantee that applies to a client’s writes in a session and its subsequent reads. Under read-my-writes, if a client commits a write in a session, it is guaranteed to observe that write (or a newer value) on later reads in that same session. The name reflects that the guarantee applies specifically to a client’s own writes: read-my-writes does not guarantee visibility into another client’s writes.
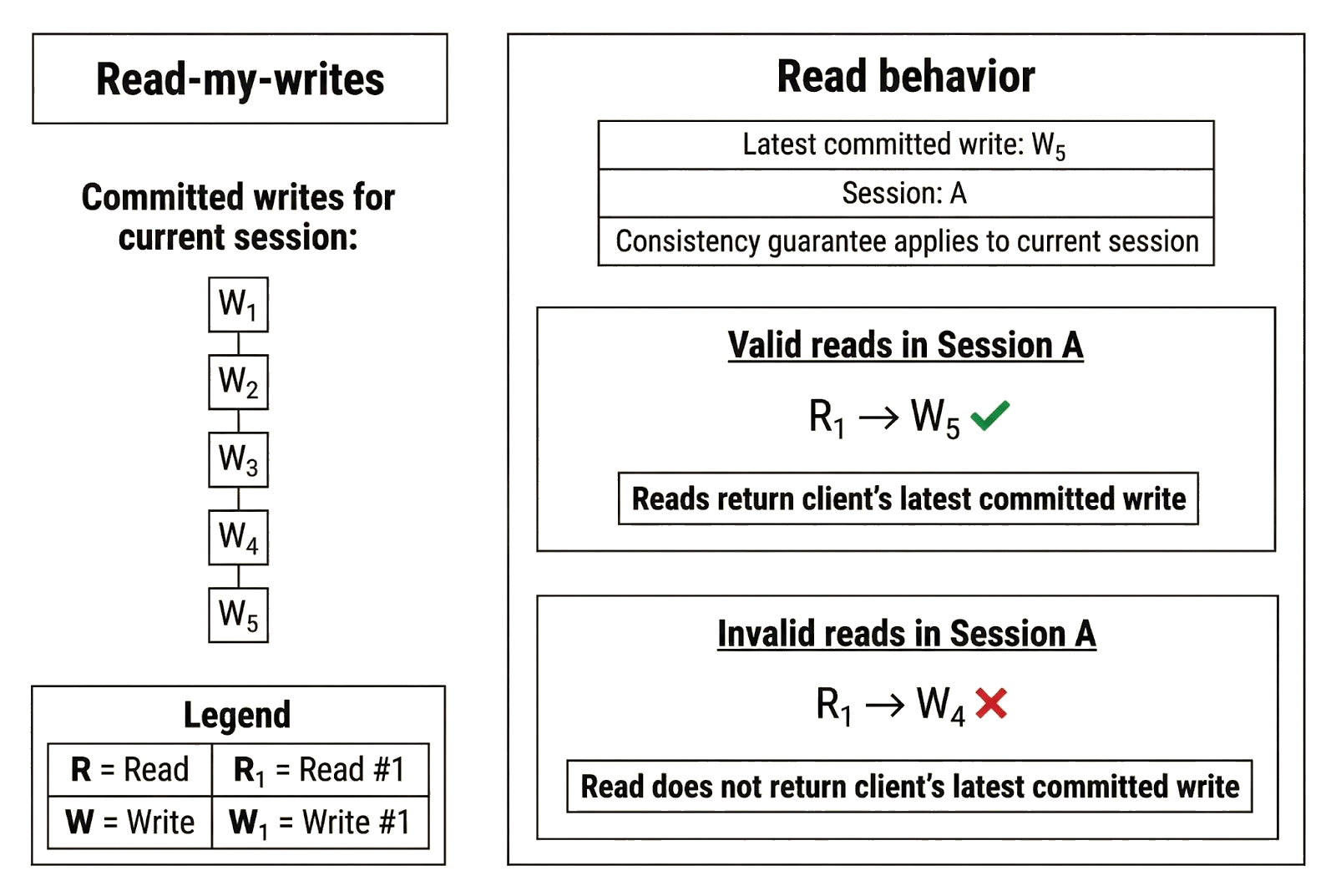
Read-my-writes is similar to monotonic reads in that it is a per-client, session-based guarantee. However, the two consistent models protect different things. Monotonic reads prevent a client’s reads from moving backward, while read-my-writes guarantees that a client can immediately observe updates it has committed through its current session.
In the bank example, Alice’s interaction with the local branch clearly illustrates read-my-writes. Alice deposits $50 into her account, increasing the balance from $100 to $150. If she immediately asks the cashier to confirm her balance, she must see $150. She is asking to observe the update she just committed (i.e., “read my write”), and the system must return a value that reflects it.
That guarantee applies only to the session through which the write occurred. If Alice checks her balance at an ATM or in the mobile app immediately afterward, she may still see $100 if those endpoints are connected to replicas that have not yet received the update. Those replicas are not bound by read-my-writes for Alice’s earlier session at the branch.
The same principle applies if Alice makes the deposit through the ATM or the mobile app instead. If the ATM session processes the deposit, then the next balance check in that same ATM session must show $150. If the mobile app processes the deposit, then the next read in that same app session must also reflect the update.
Other replicas may still lag and display a different balance. For example, after Alice deposits via the ATM, she might check her balance through another endpoint that connects to a replica that hasn’t processed the deposit and still observe $100. This is permitted. Read-my-writes only requires that the session that processed the write cannot behave as though the update never happened.
Applications of read-my-writes
Read-my-writes is commonly implemented in applications to improve the user experience. If a user performs an action such as “save,” “submit,” or “update cart,” the next read in that session should reflect that action. This pattern reinforces the core idea behind read-my-writes: once a client commits an update through a session, subsequent reads in that session must reflect it. The consistency guarantee applies to the client session that performed the write, not to every replica in the system, however.
Online shopping carts are a common example. When a user adds an item, removes one, or changes a quantity, those writes must be visible when the user views the cart afterward. If a user adds an item and then opens the cart only to find it missing, the system has violated read-my-writes. The guarantee ensures that a user’s own updates are reflected back to them, even if other parts of the system are temporarily behind.

You can see the same pattern in other systems that rely on read-my-writes. In each case, the guarantee holds within the client’s active session and ensures that writes performed through that session are reflected on subsequent reads:
- User profile management: Updated profile information must be visible to the user who made the change.
- Form submissions: After submitting a form, the user should see the updated state or confirmation.
- Commenting and posting systems: Newly created posts or comments must appear to the author immediately after posting.
- Autosave editors: The most recently saved draft must be visible to the author during the active editing session.
- User-generated lists and collections: Items added or removed must appear to the user managing the list immediately.
- Issue trackers: Newly created tickets must appear in the creator’s view after submission.
What guarantees does read-my-writes provide?
These examples discussed previously illustrate the guarantees that read-my-writes provides:
- Clients see their own writes: Once a client commits a write through a session, subsequent reads in that session must reflect that write. In the bank example, if Alice deposits $50 at the ATM, her balance there must show $150. In the shopping cart example, if a user adds an item, the cart view in that session must include it.
- Write-read consistency: A read that follows a committed write in the same session cannot return a state that predates that write. If the ATM processes Alice’s deposit, a later read from that ATM session cannot return $100. If a user updates their cart, the next read in that session cannot return the cart’s earlier state.
- Per-session, per-client consistency: Read-my-writes applies only within the session that performed the write. If Alice deposits money at the branch, the branch session must reflect it, but the ATM session may still show $100. Likewise, a user’s cart updates are guaranteed to appear in their own session, not in another user’s session.
Limitations of read-my-writes
The examples also reveal the limits of read-my-writes:
- Other replicas may serve stale data: Replicas that did not process the write may lag behind. After an ATM deposit, another endpoint may still show $100 if it is connected to a replica that has not yet applied the update. In the shopping cart example, another service backed by a different replica may not yet reflect the user’s change.
- No cross-client guarantees: Read-my-writes does not ensure that other clients see the update immediately. If Alice deposits money at the ATM, another client checking the account elsewhere may still see the old balance. Similarly, one user cannot expect to see another user’s updates reflected instantly.
- Write visibility resets with a new session: Read-my-writes applies only within the session that performed the write. If a client reconnects, switches replicas, or starts a new session, it may not immediately observe its earlier writes. For example, if Alice deposits $50 at the ATM and later checks her balance through a new mobile app session connected to a lagging replica, she may initially see $100. Likewise, if a user adds an item to a cart, then logs out and back in via a different endpoint, the cart view may briefly reflect an older state until replication catches up.
Eventual consistency
Eventual consistency is the weakest consistency guarantee available to clients reading data from a replicated system. Under eventual consistency, reads may return any value that was previously written and committed. If no new writes occur, replicas are guaranteed to eventually reflect the latest committed state, even though early reads may be stale.
Eventual consistency is more relaxed than strong consistency and the intermediate guarantees discussed earlier. We can think of consistency levels as existing on a spectrum, with strong consistency at one end and eventual consistency at the other. Strong consistency permits only one valid return value (the latest committed write). Eventual consistency permits the largest set of valid return values: any state produced by a prior committed write.
We can reuse the full bank write history from the earlier examples to explain eventual consistency. Imagine Alice opens an account at $0, deposits $25 four times to reach $100, then deposits $50 once to reach $150. She now checks her balance after the last deposit is committed. Under eventual consistency, she may see any of the following values:
- $0
- $25
- $50
- $75
- $100
- $150
Each value corresponds to a balance that was true at some point in the committed history. Some values may be stale, but eventual consistency allows stale reads as long as the returned value reflects a real, committed state.
Eventual consistency also allows replicas to apply and expose writes at different times, which can lead to confusing read behavior across endpoints. Alice might check her balance at the ATM and see $100, open the mobile app and see $75, then call the branch and be told $150. Depending on how requests are routed across replicas, she might even see the balance “jump around” across successive checks, because different reads can be served by replicas that have applied different subsets of updates.
Stale reads and temporary divergence are allowed under eventual consistency, but the system still places one basic constraint on what replicas can return: reads must reflect states produced by real committed writes. Replicas can lag, disagree, or return older values, but they cannot invent values that were never committed. In this example, no endpoint can return a balance such as $130 because it was never written.
If Alice makes no further deposits or withdrawals after reaching $150, repeated reads will eventually converge on $150 as replication completes. A given endpoint might return older balances for a while, but once updates stop and replicas finish applying the committed history, they will align on the latest committed state.
Applications of eventual consistency
Eventual consistency can feel unsafe because it places very loose constraints on what clients may observe. It is unsuitable for applications that require up-to-date data or cannot tolerate divergent views for extended periods. A bank would be unlikely to use eventual consistency for account balances, even though the example helps illustrate the model.
Despite its limitations, eventual consistency is useful in systems where temporary divergence is acceptable, and the data is not safety-critical. In exchange for weaker consistency guarantees, replicas can keep serving reads even while writes propagate.
The Domain Name System (DNS) is a real-world example of a replicated distributed system with eventual consistency guarantees. When a new domain is registered or a DNS record is updated, the change does not become visible everywhere immediately. DNS relies on resolvers in different regions to resolve domain names, and each update, such as registering a domain, setting up a redirect, or changing a record, must propagate across the global network before it becomes visible everywhere.
Resolvers cache DNS records for a fixed period (the record’s Time To Live, or TTL). During the caching window, some resolvers may continue to return older record mappings, while others return the updated mapping that reflects recent changes. Caching reduces load by allowing resolvers to avoid contacting authoritative servers for every query, and it improves uptime by allowing cached responses to be served even if parts of the network are temporarily unreachable. The trade-off is that clients may see inconsistent DNS records while updates propagate.
For instance, eventual consistency explains why a newly registered domain or a recent record change can appear to “work” in one region but not another. One resolver may have refreshed its cache and picked up the new DNS record, while another is still serving the older one until the TTL expires and forces a refresh.
Other systems with eventual consistency guarantees include:
- Social media engagement counters: Like counts, view counts, and follower numbers may temporarily differ across devices or regions, but converge once updates propagate.
- Analytics dashboards: Traffic metrics and usage statistics may lag or briefly disagree across replicas, but align once replication catches up.
- Search indexing systems: Newly published content may not appear immediately in all results, but becomes visible once indexing and propagation complete.
- Recommendation systems: Suggested content may differ across sessions or regions due to replication lag, but eventually incorporates the same interaction data.
- Content delivery networks: Updated static content may appear in some edge locations before others, but cached copies expire and refresh.
- Log aggregation systems: Newly emitted logs may appear in different monitoring views at different times, but all replicas eventually contain the same entries.
These systems tolerate temporary divergence because the data is informational rather than safety-critical.
What guarantees does eventual consistency provide?
The previous examples show the key guarantees that eventual consistency provides:
- Reads can return older committed values: Replicas may respond with stale data while updates propagate. In the bank example, Alice may see different balances depending on which endpoint serves the request. In DNS, a resolver may return the previous mapping until its cache expires.
- Eventual alignment on the latest committed state: If no new writes occur, replicas are guaranteed to converge on the most recently committed state over time. In the bank example, repeated reads eventually return $150 once replication completes. In DNS, once TTLs expire and caches refresh, resolvers converge on the updated record and return the same mapping regardless of the origin of the request.
- Reads reflect previously committed writes: Even though replicas can return stale data, they cannot fabricate states that were never committed. In the bank example, replicas may return $25, $50, $75, $100, or $150, but not $130. In DNS, a resolver may return an older record, but it must correspond to a record that was actually published; it cannot return a mapping that was never configured.
Limitations of eventual consistency
Eventual consistency allows certain anomalies:
- Stale reads are allowed: A client may receive an older committed value instead of the latest committed write. In the bank example, Alice may deposit $50 and still see $100 on a subsequent read, even from the same endpoint that processed the deposit. Eventual consistency alone does not require immediate visibility of writes. In DNS, a resolver may continue returning an older record until its TTL expires, even though a newer record has already been published.
- Writes can be observed out of order: Successive reads are not required to move forward through the write history. In the bank scenario, Alice might see $100, then $75, then $150 on different reads, depending on which replica responds and how replication progresses. Eventual consistency does not enforce monotonicity. Likewise, a DNS resolver may return an updated record on one query and an older record on another if different caches are consulted.
- Temporary divergence in views of state: Different clients, or the same client using different endpoints, may observe different states at the same moment. In the bank example, the branch may show $150 while the ATM shows $100. In DNS, one region may resolve a domain to its new address while another still resolves it to the old one. Eventual consistency places no bound on staleness and only guarantees that replicas converge on the latest committed state once writes stop.
The consistency vs. availability vs. latency tradeoff
The original CAP theorem states that in the presence of a network partition, a distributed system cannot simultaneously guarantee both strong consistency and availability. When replicas cannot communicate reliably, the system must choose: either refuse requests to preserve consistency, or respond and risk serving stale or conflicting data. In other words, CAP evaluates whether a replicated system can remain both consistent and available when replicas have diverging views of global state.
Protocol designers and application developers working with distributed (replicated) systems reason about a practical variant of this tradeoff: balancing consistency, availability, and latency. Stronger consistency ensures every read reflects the latest write, but requires more coordination across replicas, increasing latency and, under partitions or lag, reducing availability. Weaker consistency reduces coordination, improving latency and uptime while permitting stale reads and logically conflicting views of state.
Distributed systems must therefore decide where to absorb coordination cost, and that decision determines the balance between safety and performance. Stronger consistency improves safety by constraining failure modes that undermine correctness, such as stale reads and conflicting views of replicated state (for example, blockchains rely on strong consistency to prevent double-spending), but it requires more coordination and reduces performance. Weaker consistency improves performance by minimizing coordination, resulting in faster reads and writes, higher availability, and greater throughput, but weakens safety in the process.
Each consistency level thus represents a structured tradeoff between safety (data freshness and consistency of state reads) and performance (latency, availability, and throughput). We explore various consistency guarantees through the safety–performance lens in the next section.
Analyzing consistency guarantees through the safety–performance lens
1. Strong consistency
Strong consistency maximizes safety at the expense of performance. Reads always reflect the latest committed write. To enforce this, replicas must coordinate before confirming writes or serving certain reads. That coordination increases read and write latency, limits throughput, and may reduce availability during partitions, since out-of-sync replicas may refuse requests rather than serve stale or inconsistent data. Freshness is guaranteed, and coordination cost is the highest.
2. Bounded staleness
Bounded staleness prioritizes safety while trading off some performance. Reads may lag the latest write, but never beyond a defined time or version bound. The system must coordinate to enforce that bound, adding latency and synchronization overhead (for example, periodic checkpointing). Compared to strong consistency, it improves availability and throughput, but still incurs coordination costs to preserve safety within defined limits.
3. Consistent prefix
Consistent prefix maximizes performance at the expense of lower safety. Replicas may serve stale data, and clients connected to different replicas may observe different states, but reads always represent a valid prefix of the write history. Coordination cost is lower because replicas need not be fully up to date before responding, though they must preserve global write order. Latency and throughput improve compared to bounded staleness and strong consistency, but guarantees of freshness and global state agreement are weaker.
4. Monotonic reads
Monotonic reads maximize performance for reading clients while providing limited (session-level) safety. A client’s view never moves backward within a session, but different sessions may observe different states. Coordination is largely limited to tracking session progress rather than synchronizing replicas globally, which improves availability and keeps latency low. Freshness and consistency guarantees apply only within a single session and are weaker than strong consistency, bounded staleness, and consistent prefix.
5. Read-my-writes
Read-my-writes maximizes performance for writing clients while providing limited (session-level) safety. Writes committed by a client must be visible on subsequent reads in that same session. A replica may not reflect the latest global write, but it must expose the client’s own writes. Coordination is limited to the client’s session replica, though the system may need to route subsequent reads to that replica to preserve the guarantee, slightly increasing read latency and reducing flexibility compared to models that permit responses from any replica. Consistency guarantees apply only within a single session, which is weaker than strong consistency and bounded staleness.
6. Eventual consistency
Eventual consistency maximizes performance at the expense of safety. Replicas respond immediately with whatever state they have, without coordinating to ensure freshness or global ordering. It achieves the lowest read and write latencies, the highest availability, and the best throughput because operations require no coordination, and replicas may return any previously committed state for that object. Safety is weakest: reads may be stale, out of order, and inconsistent across replicas until updates fully propagate and writes stop.
Comparing consistency guarantees in distributed systems
The table below summarizes the six consistency guarantees discussed throughout this article. It serves as a practical reference for comparing their properties (read and write latency, throughput, and data freshness) and choosing the model that best fits an application’s requirements.
Conclusion
Consistency is ultimately about what clients can observe in a distributed system with replicated data. A system can enforce correct state transitions and commit only valid writes internally, yet still expose conflicting or stale views if replicas diverge. Consistency levels address this second problem by answering a practical question: How do committed writes become visible to clients without producing inconsistent views of state?
Strong consistency ensures every read reflects the latest committed write. Bounded staleness allows reads to lag the latest write, but only within a defined bound. Consistent prefix guarantees that reads respect the global ordering of writes, even if they do not reflect the latest one. Monotonic reads and read-my-writes provide session-level guarantees about how reads relate to previously observed or written values. Eventual consistency allows reads to return any previously committed value, with convergence on the latest committed state guaranteed if writes stop.
Although each consistency guarantee can stand on its own, production systems often combine multiple guarantees across different components. For example, decentralized blockchains rely on strong consistency for safety-critical operations such as block finalization, while read-heavy workflows like querying historical chain data may use bounded staleness or eventual consistency to reduce coordination and improve latency. The appropriate choice depends on where correctness is essential and where temporary divergence in clients’ views of state is acceptable.
The comparison table serves as a practical design reference. It maps application requirements to concrete consistency guarantees and makes the tradeoffs explicit. Rather than defaulting to the strongest or weakest model, developers can select the consistency level that matches the behavior their system must provide.
For deeper explanations, visual walkthroughs, and related tutorials, visit the Rialo Learn page on consistency to explore how these concepts apply to real distributed systems.